QuestionPapersHub.com
GATE-2019
Q: A certain processor uses a fully associative cache of size 16 kB. The cache block size is 16 bytes. Assume that the main memory is byte addressable and uses a 32-bit address. How many bits are required for the Tag and the Index fields respectively in the addresses generated by the processor?
- A: 24 bits and 0 bits
- B: 28 bits and 4 bits
- C: 24 bits and 4 bits
- D: 28 bits and 0 bits
GATE-2019
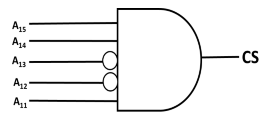
Q: The chip select logic for a certain DRAM chip in a memory system design is shown below. Assume that the memory system has 16 address lines denoted by A15 to A0. What is the range of addresses (in hexadecimal) of the memory system that can get enabled by the chip select (CS) signal?
- A: C800 to CFFF
- B: CA00 to CAFF
- C: C800 to C8FF
- D: DA00 to DFFF
GATE-2019
Q: A certain processor deploys a single-level cache. The cache block size is 8 words and the word size is 4 bytes. The memory system uses a 60-MHz clock. To service a cache miss, the memory controller first takes 1 cycle to accept the starting address of the block, it then takes 3 cycles to fetch all the eight words of the block, and finally transmits the words of the requested block at the rate of 1 word per cycle. The maximum bandwidth for the memory system when the program running on the processor issues a series of read operations is __________× 106 bytes/sec.
GATE-2019
Q: Consider the following processor design characteristics.
Q: Consider the following processor design characteristics.
I. Register-to-register arithmetic operations only
II. Fixed-length instruction format
III. Hardwired control unit
Which of the characteristics above are used in the design of a RISC processor?
- A: I and II only
- B: II and III only
- C: I and III only
- D: I, II and III
GATE-2018
Q: A 32-bit wide main memory unit with a capacity of 1 GB is built using 256M × 4-bit DRAM chips. The number of rows of memory cells in the DRAM chip is 214. The time taken to perform one refresh operation is 50 nanoseconds. The refresh period is 2 milliseconds. The percentage (rounded to the closest integer) of the time available for performing the memory read/write operations in the main memory unit is __________.
GATE-2018
Q: The instruction pipeline of a RISC processor has the following stages: Instruction Fetch (IF), Instruction Decode (ID), Operand Fetch (OF), Perform Operation (PO) and Writeback (WB). The IF, ID, OF and WB stages take 1 clock cycle each for every instruction. Consider a sequence of 100 instructions. In the PO stage, 40 instructions take 3 clock cycles each, 35 instructions take 2 clock cycles each, and the remaining 25 instructions take 1 clock cycle each. Assume that there are no data hazards and no control hazards. The number of clock cycles required for completion of execution of the sequence of instructions is ______.
GATE-2018
Q: A processor has 16 integer registers (R0, R1, .. , R15) and 64 floating point registers (F0, F1,… , F63). It uses a 2-byte instruction format. There are four categories of instructions:Type-1, Type-2, Type-3, and Type-4. Type-1 category consists of four instructions, each with 3 integer register operands (3Rs). Type-2 category consists of eight instructions, each with 2 floating point register operands (2Fs). Type-3 category consists of fourteen instructions, each with one integer register operand and one floating point register operand (1R+1F). Type-4 category consists of N instructions, each with a floating point register operand (1F).
Q: A processor has 16 integer registers (R0, R1, .. , R15) and 64 floating point registers (F0, F1,… , F63). It uses a 2-byte instruction format. There are four categories of instructions:Type-1, Type-2, Type-3, and Type-4. Type-1 category consists of four instructions, each with 3 integer register operands (3Rs). Type-2 category consists of eight instructions, each with 2 floating point register operands (2Fs). Type-3 category consists of fourteen instructions, each with one integer register operand and one floating point register operand (1R+1F). Type-4 category consists of N instructions, each with a floating point register operand (1F).
The maximum value of N is __________.
GATE-2017
Q: Consider a two-level cache hierarchy with L1 and L2 caches. An application incurs 1.4 memory accesses per instruction on average. For this application, the miss rate of L1 cache is 0.1; the L2 cache experiences, on average, 7 misses per 1000 instructions. The miss rate L2 expressed correct to two decimal places is _________.
GATE-2017
Q: Consider a RISC machine where each instruction is exactly 4 bytes long. Conditional and unconditional branch instruction use PC-relative addressing mode with Offset specified in bytes to the target location of the branch instruction. Further the Offset is always with respect to the address of the next instruction in the program sequence. Consider the following instruction sequence.
Q: Consider a RISC machine where each instruction is exactly 4 bytes long. Conditional and unconditional branch instruction use PC-relative addressing mode with Offset specified in bytes to the target location of the branch instruction. Further the Offset is always with respect to the address of the next instruction in the program sequence. Consider the following instruction sequence.
Instr. No. Instruction
i : add R2, R3, R4
i+1 : sub R5, R6, R7
i+2 : cmp R1, R9, R10
i+3 : beq R1, offset
If the target of the branch instruction is i, then the decimal value of the offset is ______
GATE-2017
Q: Instruction execution in a processor is divided into 5 stage, Instruction Fetch (IF), Instruction decode (ID), Operand Featch (OF), Execute (EX), and Write Back (WB). These stages take 5, 4, 20, 10,and 3 nanoseconds (ns) respectively. A pipelined implementation of the processor requires buffering between each pair of consecutive stages with a delay of 2 ns. Two pipelined implementations of the processor are contemplated;